Are decision trees supervised learning
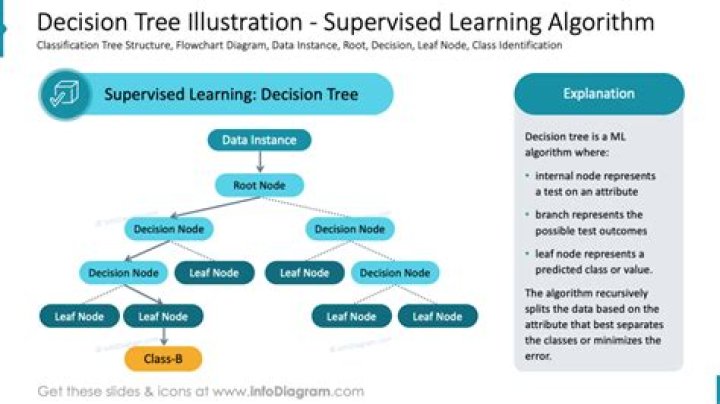
Introduction Decision Trees are a type of Supervised Machine Learning (that is you explain what the input is and what the corresponding output is in the training data) where the data is continuously split according to a certain parameter. The tree can be explained by two entities, namely decision nodes and leaves.
Is decision tree a supervised method?
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression.
Why are decision trees supervised learning?
Decision Trees (DTs) are a supervised learning technique that predict values of responses by learning decision rules derived from features. … These models learn the features directly from the data, rather than being prespecified, as in some other basis expansions.
Is decision tree an unsupervised learning algorithm?
Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems.Can decision trees be unsupervised?
Decision trees can be used for supervised AND unsupervised learning. Yes, even with the fact that a decision tree is per definition a supervised learning algorithm where you need a target variable, they can be used for unsupervised learning, like clustering.
Are decision trees binary?
A Binary Decision Tree is a structure based on a sequential decision process. Starting from the root, a feature is evaluated and one of the two branches is selected. This procedure is repeated until a final leaf is reached, which normally represents the classification target you’re looking for.
Which of the following is not supervised learning?
Unsupervised learning Unsupervised learning is a type of machine learning task where you only have to insert the input data (X) and no corresponding output variables are needed (or not known).
Which algorithm is used in decision tree?
The decision tree learning algorithm The basic algorithm used in decision trees is known as the ID3 (by Quinlan) algorithm. The ID3 algorithm builds decision trees using a top-down, greedy approach.Is decision tree a classification algorithm?
Classification is a two-step process, learning step and prediction step, in machine learning. In the learning step, the model is developed based on given training data. … Decision Tree is one of the easiest and popular classification algorithms to understand and interpret.
Can Decision Trees be used for binary classification tasks?Explanation: Decision Trees can be used for Classification Tasks.
Article first time published onWhat is the difference between supervised & unsupervised learning?
The main difference between supervised and unsupervised learning: Labeled data. The main distinction between the two approaches is the use of labeled datasets. To put it simply, supervised learning uses labeled input and output data, while an unsupervised learning algorithm does not.
Is cluster analysis supervised or unsupervised?
Unlike supervised methods, clustering is an unsupervised method that works on datasets in which there is no outcome (target) variable nor is anything known about the relationship between the observations, that is, unlabeled data.
What are the types of supervised learning?
- Regression. In regression, a single output value is produced using training data. …
- Classification. It involves grouping the data into classes. …
- Naive Bayesian Model. …
- Random Forest Model. …
- Neural Networks. …
- Support Vector Machines.
Is Knn supervised or unsupervised?
The k-nearest neighbors (KNN) algorithm is a simple, supervised machine learning algorithm that can be used to solve both classification and regression problems.
What is Diana clustering?
DIANA Hierarchical Clustering DIANA is also known as DIvisie ANAlysis clustering algorithm. It is the top-down approach form of hierarchical clustering where all data points are initially assigned a single cluster. Further, the clusters are split into two least similar clusters.
Is logistic regression supervised or unsupervised?
True, Logistic regression is a supervised learning algorithm because it uses true labels for training. Supervised learning algorithm should have input variables (x) and an target variable (Y) when you train the model .
What are decision trees commonly used for?
A Decision Tree is a supervised machine learning algorithm that can be used for both Regression and Classification problem statements. It divides the complete dataset into smaller subsets while at the same time an associated Decision Tree is incrementally developed.
What is the disadvantage of decision trees?
Disadvantages of decision trees: They are unstable, meaning that a small change in the data can lead to a large change in the structure of the optimal decision tree. They are often relatively inaccurate. Many other predictors perform better with similar data.
Which one of these is a tree based learner?
Q.Which one of these is a tree based learner?B.bayesian belief networkC.bayesian classifierD.random forestAnswer» d. random forest
Can decision trees be used for all classification tasks?
Decision Trees can be used for Classification Tasks. Explanation: None.
Can a decision tree have more than 2 splits?
Chi-square is another method of splitting nodes in a decision tree for datasets having categorical target values. It can make two or more than two splits. It works on the statistical significance of differences between the parent node and child nodes.
How are decision trees used in classification?
Decision Tree – Classification. Decision tree builds classification or regression models in the form of a tree structure. It breaks down a dataset into smaller and smaller subsets while at the same time an associated decision tree is incrementally developed. … Decision trees can handle both categorical and numerical data …
What is decision tree in artificial intelligence?
A Decision tree is the denotative representation of a decision-making process. Decision trees in artificial intelligence are used to arrive at conclusions based on the data available from decisions made in the past. … Therefore, decision tree models are support tools for supervised learning.
Is Random Forest supervised learning?
Random forest is a supervised learning algorithm. The “forest” it builds, is an ensemble of decision trees, usually trained with the “bagging” method. The general idea of the bagging method is that a combination of learning models increases the overall result.
What other algorithms based on decision tree are used as Machine Learning algorithms?
Besides tree-based, there are many other Machine Learning algorithms, such as k Nearest Neighbors (kNN), linear and logistic regression, Support Vector Machine (SVM), k-means, Principal Components Assessments, and so on.
What are supervised learning algorithms?
A supervised learning algorithm takes a known set of input data (the learning set) and known responses to the data (the output), and forms a model to generate reasonable predictions for the response to the new input data. Use supervised learning if you have existing data for the output you are trying to predict.
Which algorithm is alternative to decision tree learning algorithm?
4CatBoost: CatBoost is another Machine Learning algorithm based on the Gradient Boosting of decision trees, developed by Yandex. So same question before, why CatBoost ? a) CatBoost algorithm has shallow tree depth which results in lesser prediction time when compared to other boosting algorithms.
Is decision tree same as binary tree?
As we can see from the sklearn document here, or from my experiment, all the tree structure of DecisionTreeClassifier is binary tree. Either the criterion is gini or entropy, each DecisionTreeClassifier node can only has 0 or 1 or 2 child node.
Is decision tree only for binary classifier?
For practical reasons (combinatorial explosion) most libraries implement decision trees with binary splits. The nice thing is that they are NP-complete (Hyafil, Laurent, and Ronald L. Rivest. “Constructing optimal binary decision trees is NP-complete.” Information Processing Letters 5.1 (1976): 15-17.)
Can decision trees be used for regression tasks?
Decision Tree algorithm has become one of the most used machine learning algorithm both in competitions like Kaggle as well as in business environment. Decision Tree can be used both in classification and regression problem.
What is not common between supervised and unsupervised learning?
The supervised and Unsupervised learning mainly differ by the fact that supervised learning involves the mapping from the input to the essential output. On the contrary, unsupervised learning does not aim to produce output in the response of the particular input instead it discovers patterns in data.